

The Gap Between Understanding and Action
There's no shortage of AI demos in insurance. Transcribe a call, summarize a document, co-pilot an adjuster. Impressive technology, marginal operational impact.
The reason is structural: most insurance AI stops at understanding. It can interpret what a policyholder said. It can classify a loss type. But it can't do anything - can't create a claim in Guidewire or Snapsheet with the right codes, can't dispatch a mitigation vendor, can't execute a multi-step evidence chase with governed write-back to the carrier's systems of record, can't submit a quote to a rater engine with the right driver and vehicle details, can't process a policy endorsement and write the change back to the AMS.
Closing that gap requires a system of action - software that doesn't just track workflows but executes them, making constraint-aware decisions and performing governed write-back, escalating to humans when risk or ambiguity exceeds defined thresholds. Not a chatbot. Not a copilot. A domain-specific reasoning agent that can plan multi-step work, use tools to complete real work, and improve through observed outcomes.
We think about this as a first mile, middle mile, last mile problem. The first mile is intake and structuring. The middle mile is supervision and trust. The last mile - the hardest - is governed execution under domain constraints.

Each layer has distinct requirements, and skipping any of them is why most insurance AI never graduates to production.
The First Mile: Multimodal Intake and Insurance-Native Structuring
Stateful multimodal communication. Any system of action for insurance has to solve voice - it's still the dominant channel for FNOL and complex servicing. But a single claim often spans multiple phone calls, SMS photo uploads, and emailed documents. What's required is low-latency voice orchestration, with SMS, webchat, and email as coordinated channels sharing a persistent interaction context, along with insurance-specific guardrails and multi-agent composition. Generic guardrails aren't sufficient. Insurance demands domain constraints: never provide coverage advice, never make liability determinations, enforce state-by-state disclosures.
Beyond guardrails, a multi-vehicle injury collision requires a fundamentally different agent graph than a water leak needing emergency mitigation - different tool permissions, different escalation thresholds, different authority limits. The same principle applies across sales and servicing: an auto quoting flow that needs to collect vehicles, drivers, and coverage preferences before submitting to a rating engine is a fundamentally different agent composition than a policyholder calling to add a driver to an existing policy. The latter requires identity verification, policy lookup, and a governed write-back to the AMS. What's needed is a multi-agent architecture with purpose-built reasoning agents (FNOL intake, coverage verification, injury triage, mitigation dispatch, quoting, policy servicing) composed dynamically per scenario, each with defined contracts and its own set of performance metrics and evaluations. This is the architectural direction we're pursuing.
The Canonical Domain Model (CDM). This is the layer most platforms skip, and we believe it's the single most important architectural decision for making the last mile possible. The idea is straightforward: a normalized, insurance-native schema that represents claims, policies, vehicles, losses, injuries, and liability as first-class domain objects - not generic data structures with insurance labels bolted on. We're building the CDM to serve as the canonical intermediate representation between what an AI agent understands from a conversation and what a carrier's systems of record need to operate on. That means bidirectional, carrier-specific mappings: structured extraction as inputs (turning messy voice, email, and document inputs into typed domain objects with confidence scores), and deterministic transformation as outputs (producing payloads that match the carrier's specific field formats, code tables, and workflow states).
Our Customer Mapping layer then applies deterministic, carrier-specific transformations - producing native payloads for core systems like Guidewire with the correct code table lookups, field formatting, and jurisdiction codes. Every mapping is versioned, tested, and logged end-to-end. When engineers need to extend the domain model or build new agent capabilities, they do so through Liberate Agent Foundry - our code-native SDK - using whatever AI coding tools their team already works in (Cursor, Copilot, Claude Code). Everything built in Agent Foundry is automatically reflected in Agent Foundry Studio, a visual twin representation in Supervisor where operations and business users can inspect, validate, and govern the same logic without reading code. This is how AI Agent Engineers and carrier teams work effectively with the system of action together - engineers build in code, the organization governs through the visual interface, one source of truth.
The Middle Mile: Supervision and Trust Infrastructure
The Control Tower. Trust is an engineering problem. What's required is a human-in-the-loop layer with operational teeth: a Drafts & Approvals queue where actions exceeding confidence thresholds surface for review; a Reasoning Trace logging every decision with evidence, rules triggered, alternatives considered, and confidence scores; and Workflow Progression showing claim lifecycle status with AI-recommended next actions. We're building Supervisor - our Control Tower - as a core platform component for claims managers and operations leaders, not ML engineers.
Insurance-specific evals. The core eval problem isn't "did the model generate good text" - it's "did it produce a correct claim object." This requires field-level precision and recall against golden datasets, entity extraction F1 per insurance entity class, and code table mapping accuracy. We're investing heavily here because this eval infrastructure is the unlock for carrier trust and, ultimately, for expanding agent autonomy.
Bringing It to Life: Forward-Deployed Engineering
Building a platform is half the challenge. Encoding carrier-specific operational knowledge into agent behavior is the other half.
Liberate's AI Agent Engineers and AI Agent PMs work inside carrier organizations across three workstreams: playbook capture - extracting SOPs from documentation and institutional knowledge into executable playbooks; enterprise AI voice consistency - establishing unified tone, disclosure language, and empathy calibration across claims, servicing, sales, and internal tooling; and integration architecture - designing CDM mapping topology, approval flows, and write-back targets with carrier engineering teams.
The progression we're building toward: forward-deployed teams build initially, carrier teams take over iteration through the Control Tower, and eventually carriers operate their own agent fleet with self-service configuration, staged rollouts, and regression gating. This is how AI investment compounds rather than creating vendor dependency.
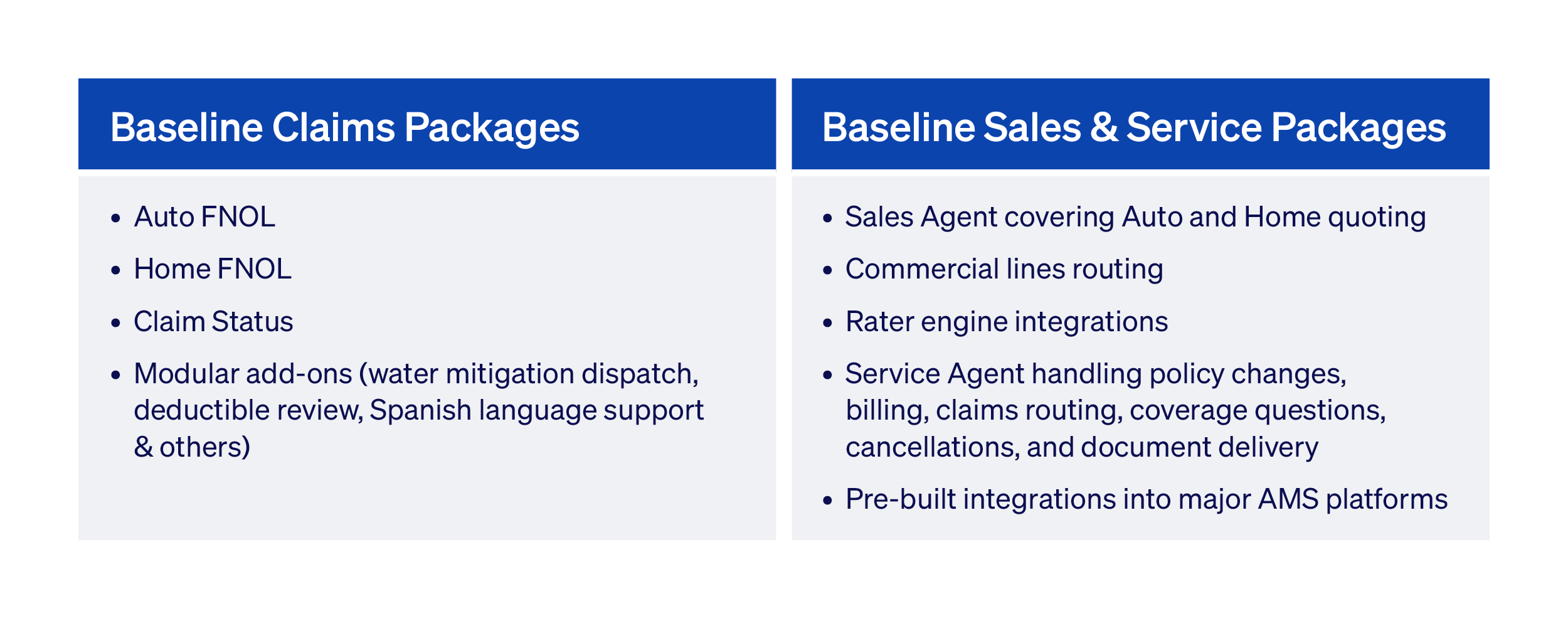
Liberate ships with production-ready intake packages across claims, sales, and servicing. On the claims side: Auto FNOL, Home FNOL, Claim Status, and modular add-ons like water mitigation dispatch, deductible review, and Spanish language support - each composed of purpose-built sub-agents with out-of-the-box question flows, loss type classifications, and system mappings that can go live in weeks.
On the sales and servicing side: a Sales Agent covering Auto and Home quoting, commercial lines routing, and rater engine integrations, and a Service Agent handling policy changes, billing, claims routing, coverage questions, cancellations, and document delivery - with pre-built integrations into major AMS platforms.
These packages represent the baseline: the best version of how these workflows should run, distilled from deployments across carriers and agencies, but SOPs are carrier-specific and often agency-specific.

Liberate's AI Agent Engineers and AI Agent PMs work inside carrier and agency organizations across three workstreams: playbook capture - taking the baseline packages and tuning them against your specific SOPs, authority limits, state and LOB constraints, and exception handling patterns; enterprise AI voice consistency - establishing unified tone, disclosure language, and empathy calibration across claims, servicing, sales, and internal tooling; and integration architecture - designing CDM mapping topology, approval flows, and write-back targets with carrier engineering teams.
The progression we're building toward: forward-deployed teams deploy the baseline packages and customize for your environment initially, carrier teams take over iteration through the Control Tower, and eventually carriers operate their own agent fleet with self-service configuration, staged rollouts, and regression gating. This is how AI investment compounds rather than creating vendor dependency.
The Last Mile: The System of Action
Most insurance AI today is basic text summarizing or data collection - an agent can synthesize information or ask questions and fill in a form. The last mile is what happens after: creating claims with correct codes, dispatching vendors, executing evidence chases - all under authority limits and carrier workflow rules. This is where reasoning has to mean something concrete.
Playbook-aware governed autonomy. What's needed is a way to formalize carrier playbooks as governed decision frameworks - not rigid scripts, but structured playbooks with branching logic, confidence thresholds, and explicit authority boundaries. Water loss → emergency mitigation path. Multi-vehicle injury → complex triage with risk flagging and human routing. Playbooks need to be versioned, testable, and simulatable before touching production. We're building a Playbook Simulation environment for exactly this.
From deterministic execution to outcome-trained reasoning. This is the data science frontier. Carriers start with rule-based tool execution. Graduate to playbook-governed decision-making with contextual judgment. The target state is outcome-trained autonomy - where the system learns from supervisor overrides as structured feedback (adjusting constraint thresholds, not naive fine-tuning), builds causal attribution models connecting early decisions to downstream outcomes (cycle time, leakage, litigation), and monitors for drift with dynamic autonomy tiering that automatically degrades to conservative behavior when performance slips. Each claim cohort gets its own eval suite, thresholds, and regression gates - graduated autonomy, not a binary switch.
The maturity curve. The same infrastructure supports every stage: Level 1 data collection, Level 2 deterministic execution with approval, Level 3 playbook-governed autonomy, Level 4 outcome-trained resolution. Same Control Tower, same eval framework, same CDM, same write-back semantics. The carrier progresses on their own timeline without re-platforming.

What We're Building
The gap in insurance AI isn't model capability. It's the domain-specific infrastructure to turn capability into operational execution: a canonical data model bridging AI and core systems, a multi-agent architecture for real insurance complexity, an evaluation framework measuring what matters operationally, a supervision layer building trust through measurement, and a governed autonomy framework expanding agent authority as it's earned.
To learn more about the Liberate System of Action, download our white paper



